
An introduction to CodeQL and data flow analysis
I'll be honest — when I sat through my first-year Discrete Mathematics course, there were plenty of times when I wondered if I'd ever use any of it in the real world. I'm going to assume that a significant proportion of my audience is studying, has studied, or is about to study Computer Science, where discrete mathematics is a core part of the foundational curriculum. If you're in that boat, you might be wondering the same thing.
Recently, I've worked extensively with CodeQL — a powerful static analysis tool developed by GitHub — to roll out code scanning as part of CI/CD pipelines. At the core of this is the QL language, which is used to write queries that reason about code. Compared to its competitors, CodeQL excels at taint tracking and data flow analysis, which is a fancy way of saying that it's really good at highlighting how potentially malicious or insecure data can flow through your code and end up in a dangerous place that introduces a security vulnerability.
Now, do you need to understand the mathematics behind CodeQL to use it effectively? Not necessarily. But at its core, QL is a declarative logic programming language, and thus it's built on a foundation of set theory and predicate logic. I like to understand the tools I use, so I wanted to write a little about how CodeQL and data flow analysis works under the hood. This is by no means a comprehensive guide, but I hope it serves as a useful introduction for those who are curious!
An introduction to CodeQL
QL is a declarative language. This means that queries are written in a way that describes the desired result, rather than the steps to achieve it. This is in contrast to imperative languages like Python or Java, where you write code that describes the steps to achieve the desired result.
Here's how a typical CodeQL analysis workflow might look like:
- The source code is compiled into a database. This database contains the relational representation of the codebase, which includes information about the structure of the code, the control flow, and the data flow.
- The CodeQL engine runs QL queries against the database, similar to how one might run SQL queries against a relational database, to find patterns in the code that match the query.
- The results are exported into the SARIF format, which can be consumed by CI tools or custom integrations.
In this sense, CodeQL is a lot like SQL. One might even recognise the similarities in the basic syntax:
import javascript
from Function f
where not exists(CallExpr c | c.getCallee() = f)
select f, "This function is never called."This query, for example, finds all functions that are never called in a JavaScript codebase. Notice the exists existential quantifier, which checks if
there is at least one CallExpr that calls the function f.
Notice also that QL is object-oriented. CallExpr::getCallee() returns an Expr, which could be a FunctionExpr (which is a Function). However, keep
in mind that class objects in the traditional sense (allocating memory to hold the state of an instance of a class) don't exist in QL. Here, classes
are more like abstract data types that describe sets of existing values.
Predicates and Binding
Binding refers to the process of associating variables in a query with sets of values from the CodeQL database. A common mistake is to think of variables in the imperative sense, where they can be assigned any value at any time. CodeQL works on relations between values, so variables are bound to finite sets of values that already exist.
Let's walk through a simple example.
import javascript
predicate sumsTo42(Expr x, Expr y) {
x instanceof ConstantExpr and y instanceof ConstantExpr and
x.getIntValue() + y.getIntValue() = 42
}
from Expr x, Expr y
where sumsTo42(x, y)
select x, yFirst, consider the domain of all elements in the CodeQL database, where is finite.
We have introduced a predicate sumsTo42 that takes two Expr objects and checks if their integer values sum to 42.
Let:
- .
- .
Then, the predicate sumsTo42 evaluates to a set of two-tuples:
Now, the from clause binds the variables x and y to the set of all Expr objects in the database, i.e. . The where clause then filters this set to
only include those tuples that satisfy the predicate . The result is
Notice that the predicate is a finite set, because its arguments are of a finite type! (Expr refers to the finite set of all expressions in the CodeQL database.)
Because the query results rely on checking for membership in predicate sets, all predicates must evaluate to a finite set — otherwise it's impossible to evaluate
the query in finite time.
For example, this query won't work:
import javascript
predicate sumsTo42(int x, int y) { x + y = 42 }
from Expr x, Expr y
where
x instanceof ConstantExpr and
y instanceof ConstantExpr and
sumsTo42(x.getIntValue(), y.getIntValue())
select x, ybecause the predicate arguments aren't bound! Clearly, is bound iff is bound, and vice versa. Since there are no other operators in the predicate that could bind either variable, the predicate is not well-defined (attempting to evaluate an infinite subset of ) and the compiler will helpfully throw an error.
Data flow analysis and taint tracking
The real power of CodeQL lies in its ability to track data flow through a codebase. This is particularly useful for security analysis, where one might want to find out how user input flows through the system and ends up in a dangerous place.
To do this, CodeQL constructs a data flow graph that represents how data flows through the code (e.g. passed between variables, functions, and expressions). Note that this is not the same as an abstract syntax tree, which represents the syntactic structure of the code. Here's an example:
function foo(p) {
let x = 0
if (p) {
x = p.f
}
return x
}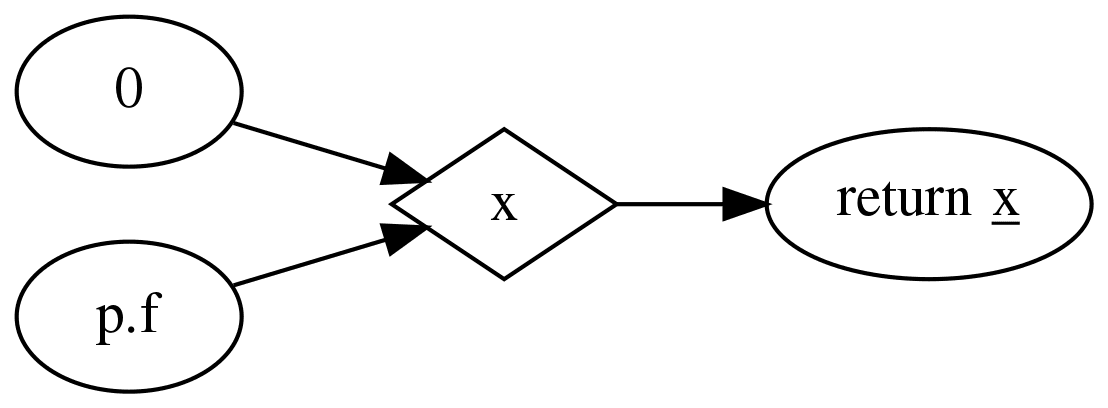
Notice how the assignments are represented as edges, and the conditionals are not present in the graph. We don't care that x is 0 if p is falsy —
we just need to know that x has possible values of 0 and p.f.
Taint tracking takes it a step further by marking certain data as "tainted", and propagating this through derived data. For example, if y = foo(p),
and p is tainted, then y is also tainted, because it derives from p. This makes sense when analysing bugs and vulnerabilities, because if p is untrusted
user input, then y must also be treated as untrusted.
This is a fundamentally recursive task: given some propagation rules that determine whether the result of some operation, given tainted inputs, is also tainted, explore the program's control flow until no more tainted data can be found.
In other words, find where is a vector of "In's" and "Out's" representing the set of variables tainted before and after each statement, and is a function that applies the propagation rules. We want the least fixed point, i.e. the smallest such that .
A partial order is a relation that is reflexive, transitive, and antisymmetric. We can define a partial order among vectors of sets:
It's easy to see that this is a partial order: it is reflexive (since ), transitive (since ), and antisymmetric (since ).
A function is monotone over the partial order if, for all and ,
What does this say? It means that "larger" or equal inputs lead to "larger" or equal outputs. Here, is monotone because applying the propagation rules to a "larger" or equal set of "current" tainted variables yields a "larger" or equal set of new tainted variables . To see this, consider that once a variable is marked as tainted, it remains tainted, while an untainted variable can become tainted with the discovery of new tainted variables.
This ensures that repeating will progressively increase the set of reachable expressions towards convergence at the least fixed point, so this provides us with a way to compute the least fixed point of .
Formally, this is Kleene's fixed-point theorem. The least fixed point of the monotonic function is the limit of the ascending chain obtained by applying repeatedly starting from the least element (here, the empty set):
where is the -fold composition of with itself, and denotes the least upper bound.
To see this, consider the sequence , .
Since is monotone, we have . Consider the last element of the chain, . , otherwise it is not the last element. Therefore it is a fixed point.
Now consider an arbitrary fixed point of . In the base case, . Also,
so by induction, for all . In particular, , so is at least as "small" as any other fixed point, and thus the least fixed point.
Writing a taint tracking query
Let's walk through a CodeQL query that looks for basic DOM-based XSS vulnerabilities in a JavaScript codebase. To start, we need to define a configuration for taint tracking:
class UnsafeDOMManipulationConfiguration extends TaintTracking::Configuration {
UnsafeDOMManipulationConfiguration() { this = "UnsafeDOMManipulationConfiguration" }
}Now, we need to define the sources. These are the places where untrusted data first enters the program. In this case, we're looking for
RemoteFlowSource (data from e.g. a request parameter), ClientRequest::Range (data from a HTTP response), and SomeOtherSource
(a custom source that we've defined elsewhere).
override predicate isSource(DataFlow::Node source) {
source instanceof RemoteFlowSource or
source instanceof ClientRequest::Range or
source instanceof SomeOtherSource
}These are used in the first iteration, , to mark all variables directly tainted by these sources. In the following iterations, variables that are derived from these sources are also marked as tainted.
Next, we need to define the sinks. These are the places where tainted data can cause harm. Eventually, we want to find all paths from any source to any sink, and those will be the results of our query.
// Sink functions from https://web.dev/articles/trusted-types
override predicate isSink(DataFlow::Node sink) {
// Direct assignment to innerHTML or outerHTML
exists(DataFlow::PropWrite pw |
pw.getPropertyName() in ["innerHTML", "outerHTML"] and
sink = pw.getRhs()
)
or
// Element.insertAdjacentHTML()
exists(DataFlow::MethodCallNode call |
call.getMethodName() = "insertAdjacentHTML" and
sink = call.getArgument(1)
)
or
// Direct assignment to iframe.srcdoc
exists(DataFlow::PropWrite pw |
pw.getPropertyName() = "srcdoc" and
sink = pw.getRhs()
)
or
// document.write() and document.writeln()
exists(DataFlow::MethodCallNode call |
call.getMethodName() in ["write", "writeln"] and
call.getReceiver() = DOM::documentRef() and
sink = call.getArgument(0)
)
or
// DOMParser.parseFromString()
exists(DataFlow::MethodCallNode call |
call.getMethodName() = "parseFromString" and
call.getReceiver().getALocalSource() instanceof DataFlow::NewNode and
call.getReceiver().getALocalSource().(DataFlow::NewNode).getCalleeName() = "DOMParser" and
sink = call.getArgument(0)
)
or
sink instanceof DomBasedXss::TooltipSink
}This defines which nodes in the data flow graph are considered sinks. In this case, we are identifying methods that can be used to inject
untrusted data into the DOM, such as innerHTML, outerHTML, insertAdjacentHTML, srcdoc, document.write, document.writeln, and DOMParser.parseFromString.
When untrusted data reaches these sinks, it can be used to execute arbitrary JavaScript code in the context of the page.
After the least fixed point is computed (and we have the completed set of all tainted elements in the program), we can then evaluate the sinks against this set of tainted elements to determine of any tainted data can reach a sink. If so, we have a potential vulnerability.
from DataFlow::PathNode source, DataFlow::PathNode sink, UnsafeDOMManipulationConfiguration config
where config.hasFlowPath(source, sink)
select sink.getNode(), "Potentially unsafe DOM manipulation with $@.", source.getNode(),
"untrusted data"Expanding the propagation function
Sometimes, the default taint steps are insufficient to capture the desired propagation. One might extend this by overriding isAdditionalTaintStep:
override predicate isAdditionalTaintStep(DataFlow::Node pred, DataFlow::Node succ) {
exists(DataFlow::ArrayCreationNode array |
pred = array.getAnElement() and
succ = array
)
or
exists(DataFlow::MethodCallNode find |
find.getMethodName().regexpMatch("find|filter|some|every|map") and
pred = find.getReceiver() and
succ = find.getCallback(0).getParameter(0)
)
}This propagates taint through array elements and array methods like find, filter, some, every, and map.
One might also want to stop propagation of taint at a sanitization step. When a node is a sanitizer, its output is considered untainted, even if the input is tainted.
This can be done by overriding isSanitizer:
override predicate isSanitizer(DataFlow::Node node) {
node = DataFlow::moduleImport("dompurify").getAMemberCall("sanitize")
}Here, we are considering the sanitize method from the DOMPurify library as a sanitizer.
These modify our propagation function to include or exclude desired nodes when propagating taint.
Aside: transitive closures
CodeQL has built-in support for transitive closures, which is pretty cool.
The transitive closure of a relation is the smallest relation that contains and is transitive. Formally, is the intersection of all transitive relations that contain . This can be defined inductively:
The reflexive transitive closure is similar, but includes the identity relation:
In CodeQL, we can use the + operator to denote the transitive closure of a predicate, and the * operator to denote the reflexive transitive closure. For example:
predicate isReachableFrom(BasicBlock start, BasicBlock end) {
end = start.getASuccessor*()
}This predicate evaluates to the set of all (start, end) pairs such that end is reachable from start by following zero or more edges in the control flow graph.
Conclusion
This is my humble attempt to pen down my mental model of how CodeQL works under the hood, which helps me to visualize how my queries are executed and how the results are derived. It's a really interesting and powerful tool that, while lacking the user-friendliness of some other static analysis tools, makes up for it with its flexibility and expressiveness.